

Chinese Open-Source Has Entered America’s AI Products
What's new? What's original in the age AI? Kimi + Cursor Saga


IY: The question of who copied whom in AI is not really a debate on technical reality. It is more on who gets to call the shots on the narrative. In this piece, Peiyue looks at what the Cursor-Kimi saga tells us about copying, credit, and power in the AI industry. Moonshot AI played it well. A company that could have dragged Cursor through a very public licensing dispute chose to reframe the whole thing and it was a good move. But one good move is not the same as calling the shots. That kind of power is built gradually, through decisions that compound over time, through setting terms that others have to respond to. When the strongest play available to a Chinese lab is still to be gracious about not crediting their work, it is worth asking who is actually setting the terms here.
Chinese Open-Source Has Quietly Entered America’s AI Products
By Peiyue Wu
Director Chloé Zhao said in an interview about her new production, an adaptation of Hamlet. When asked why she wasn’t working on something “original,” she pushed back on the premise outright.
“The word original, the root of that word, orīgō, it means old,” she said. “Original doesn’t mean new. We have a sort of misunderstanding of what the word original means.”
She was talking about Hollywood. But she could have been describing the AI industry.
Back in February, OpenAI and Athropic accused DeepSeek, MiniMax, and Moonshot AI of “free riding” their models through distillation. Chinese labs allegedly spun up thousands of accounts to scrape US models, and used the outputs to train their models without paying the full cost of building from scratch. It neatly fits into a well-worn narrative: American innovation versus Chinese imitation.
Then two weeks ago, the dynamic flipped and Cursor, a leading US AI coding startup, was caught building its newly launched model Composer 2 on top of Kimi K2.5, a Chinese open-source model from Moonshot AI. Cursor initially did not disclose it, and the issue came into light after an X user claimed the model was essentially Kimi K2.5 with reinforcement learning layered on top. The post quickly went viral, amplified by Elon Musk’s blunt reply: “Yeah, it’s Kimi 2.5.”

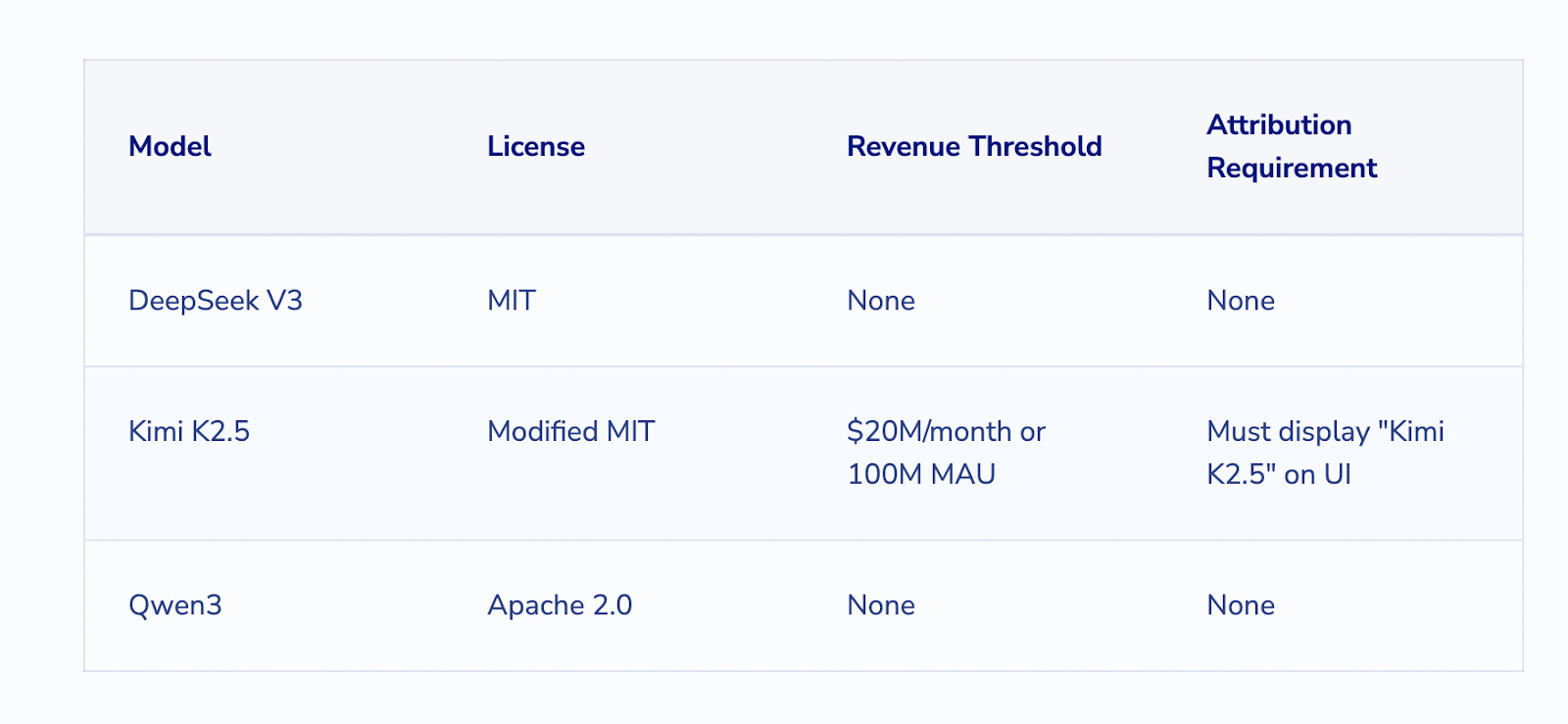
Moonshot AI’s Head of Pretraining posted a technical breakdown showing Composer 2’s tokenizer was identical to Kimi’s. The now deleted post demanded a response from Cursor on why the company had neither credited the model nor followed its license terms. The terms require any product exceeding $20 million in monthly revenue to display “Kimi K2.5” in its interface. Cursor’s annualized revenue reportedly exceeded $2 billion.
By contrast, DeepSeek and Alibaba’s Qwen do not impose similarly strict requirements on large-scale commercial use. Qwen, which had been releasing open-weight models well before DeepSeek’s V3 launch, has been one of the most widely used base models on Hugging Face
Under pressure, Cursor’s VP of Developer Education, Lee Robinson, acknowledged Kimi K2.5 had been used as a base and admitted the lack of attribution was a mistake, while emphasizing “only ~1/4 of the compute spent on the final model came from the base, the rest is from our training.” He said Kimi was chosen simply because it was “the strongest” among evaluated models.
In a surprising reversal, Moonshot AI responded graciously, reframing the episode as an “authorized commercial partnership.” For the Chinese lab, the episode lands as a near-perfect branding moment.
Both Chinese distillation and Cursor building on Kimi are forms of learning from someone else’s work, which is in the spirit of open source; but the key difference is who gets the upper hand at owning the narrative.
Who Gets to Define “Copying”?
Cursor’s reluctance to disclose its use of Kimi K2.5 reveals competing priorities: investors’ obsession with original ideas and speed to market, and the discomfort of admitting dependency on Chinese technology and the geopolitical risks that come with itwith. Cursor is purportedly targeting a $50 billion valuation in its next round. “Built on Chinese open-source” doesn’t fit neatly into that pitch deck.
But before accepting the idea that building on someone else’s work slashes enterprise value, it’s worth asking what really counts as copying.
When OpenAI trained GPT on the entire internet without compensating the individual authors, was that not also a form of extraction? When every major model ingests the creative output of millions and then monetizes the result, who is truly free riding on whom?
Accusations against Chinese labs rely on defining a model’s outputs as proprietary. Applied consistently, that logic would implicate any large model trained on copyrighted human work without consent. When the things making a model powerful — its architecture, its weights, its training algorithms, the chips running underneath — have been fiercely protected as proprietary intellectual property. But the billions of data points that actually teach the model how to think — every article ever written, every piece of code ever shared, every question a user typed into a chat interface, every creative work fed into a training pipeline — that, apparently, belongs to no one. This kind of framework protects creation only once it becomes corporate infrastructure.
The messages behind China’s open-source
Kimi K2.5 is certainly not the first Chinese model adopted by Silicon Valley. It might just have attracted the most attention. Earlier versions of Cursor had already shown traces of DeepSeek, and just weeks ago, Rakuten’s flagship AI model in Japan was found to be built on DeepSeek V3, despite being presented as domestically developed. DeepSeek, however, did not require the same “credit” in its licensing policy.
Chinese labs open-source their weights for developers to download and self-host. But for smaller companies and individual developers who lack the infrastructure such as computing power to run models locally, the commercial API remains the practical option. Chinese model APIs are priced dramatically below their US closed-source equivalents. Open-source release thus builds familiarity and trust, which ultimately leads to customer acquisition. The results are measurable. On aggregation platforms like OpenRouter, Chinese models have begun to overtake US models in total API call volume. Take Kimi as an example, its overseas revenue has exceeded its domestic revenue.
We may soon see more Chinese models embedding themselves into global products and, in cases like this, becoming the invisible layer inside companies that are still publicly positioned as their rivals.
Unlike goods subject to tariffs, or apps subject to data sovereignty concerns, Chinese models earning dollars through API calls have not yet attracted significant U.S. regulatory attention. That window won’t stay open forever. But for now, it’s open.
 | A guest post by
|
The LLM era is no longer only American in nature. Chinese companies have compelling offerings. For instance, Chinese hyperscaler Alibaba claim to be able to have models that are comparable to their American counterparts, yet needs 82% fewer Nvidia processors to run.
Even Silicon Valley companies are using Chinese LLM models over the likes of ChatGPT or Anthropic. The news that Airbnb opted to use Alibaba’s open-source Qwen AI model over ChatGPT was a milestone event.
US technology sector investors are using the Kimi K2 model because it was ‘way more performant and much cheaper than OpenAI and Anthropic’.
China benefits from much cheaper model training cost per token. The open-source models can be run on private infrastructure, keeping sensitive data inhouse and ensuring ‘corporate sovereignty.
In the global south, China’s technology companies have corporate and government business relationships built up over years. Their combination of low cost combined with trusted relationships would reduce American hyperscaler opportunities for global expansion.
While US companies have access to more powerful chips, sanctions against Chinese companies aren’t effective with Nvidia chips being smuggled into China and heavy computing work like model training being run in data centres based in other Asian countries, notably Malaysia.
More here:
https://renaissancechambara.jp/2026/01/06/the-dot-llm-era/
I’m pretty sure “built on Chinese AI” will be a plus for any IPO’s in the near future!😂🤣